
Choix techniques
Ce logiciel d’ETL est conçu pour migrer les données d’une GED à une autre en conservant les métadonnées associées.
Découvrez à quoi sert ce service sur cet article.
Sommaire
Technologies choisies




Usage
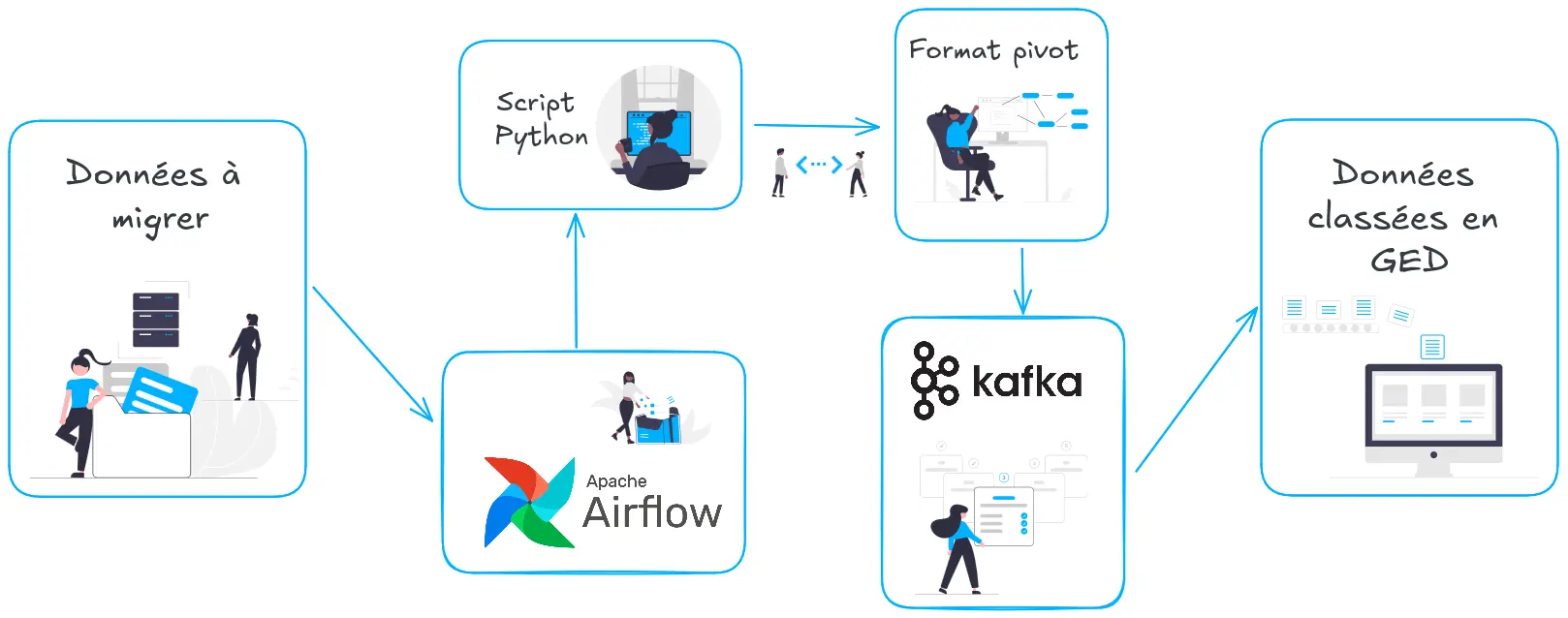
Nous avons fait le choix d’une solution basée sur des logiciels libres robustes Apache Airflow1 et Apache Kafka2. Nous avons souhaité rendre ce logiciel paramétrable en fonction des besoins de manière simple et efficace pour que chacun gagne en productivité. Notre solution permet d’interrompre le processus sans perdre ce qui a déjà été traité et peut adapter son rapport temps/charge pour ne pas impacter un serveur de production tout en travaillant en tâche de fond.
Construction du logiciel
Extraction
On utilise Airflow1, un outil standard, avec des scripts Python3. Avec cela, on a développé un format pivot en JSON4, qui décrit ce qu’est un fichier. Ce format pivot nous permet ensuite d’aller lire ou d’écrire depuis n’importe quelle source. On peut s’adapter à n’importe quelle source de données, que ce soit une API REST, une interface WebDAV, un serveur de fichier ou même scraper un site internet, etc.
Transformation
On va extraire les métadonnées de cette source et ensuite :
- il faut définir une règle de mapping vers notre modèle de données source,
- il nous faut une règle pour définir le chemin de destination de ces nouvelles données.
Avec ces informations, nous écrivons un code qui va générer un fichier JSON (qu’on appelle le fichier pivot). Il va décrire l’objet dans son ensemble, sa source et les métadonnées de destination. Ensuite, ce fichier au format pivot, on va l’envoyer à nos injecteurs et l’injection est automatique.
Chargement (load)
L’injection passe par une file Kafka2 qui va recevoir les informations et les injecter vers le serveur de réception selon les pré-requis du client (impact sur la production, ressources serveurs disponibles, reprise de données ou injection au fil de l’eau, etc.).
L’application sur Alfresco
Sur Alfresco spécifiquement, les métadonnées d’un serveur non maintenu seront converties pour respecter les bonnes pratiques d’une arborescence Alfresco. Cette solution permet de garder la date de création du fichier là où les autres méthodes copient les informations et indiquent une création au moment de la copie.
Consultez notre cas d’usage ETL d’Alfresco vers Alfresco pour en savoir plus.
En savoir plus
Articles connexes
Définitions en rapport avec l'article
- ETL
- c’est le nom générique des outils pour faire de la reprise de données. Ça veut dire Extract-transform-load (extraction, transformation et chargement)
- JSON
- JSON (JavaScript Object Notation – Notation Objet issue de JavaScript) est un format léger d’échange de données.4
- Airflow1
- c’est une plate-forme de gestion de flux de travail open source 5
- Kafka2
- projet open source sous Apache License 2.0 : “logiciel de traitement de flux pour la collecte, le traitement, le stockage et l’analyse de données à grande échelle”. 6
Notes de pas de page
Apache, Apache Airflow, and the Apache Airflow logo are registered trademarks or trademarks of The Apache Software Foundation in the U.S. and/or other countries. ↩︎ ↩︎ ↩︎
Apache, Apache Kafka, and the Apache Kafka logo are registered trademarks or trademarks of The Apache Software Foundation in the U.S. and/or other countries. ↩︎ ↩︎ ↩︎
Python and PyCon are trademarks or registered trademarks of the Python Software Foundation. ↩︎
Source : https://www.json.org/json-fr.html ↩︎ ↩︎
Source traduite du site web d’Apache Kafka : https://kafka.apache.org/powered-by ↩︎