
Changer d’outil rapidement avec notre module de reprise de données
Sommaire
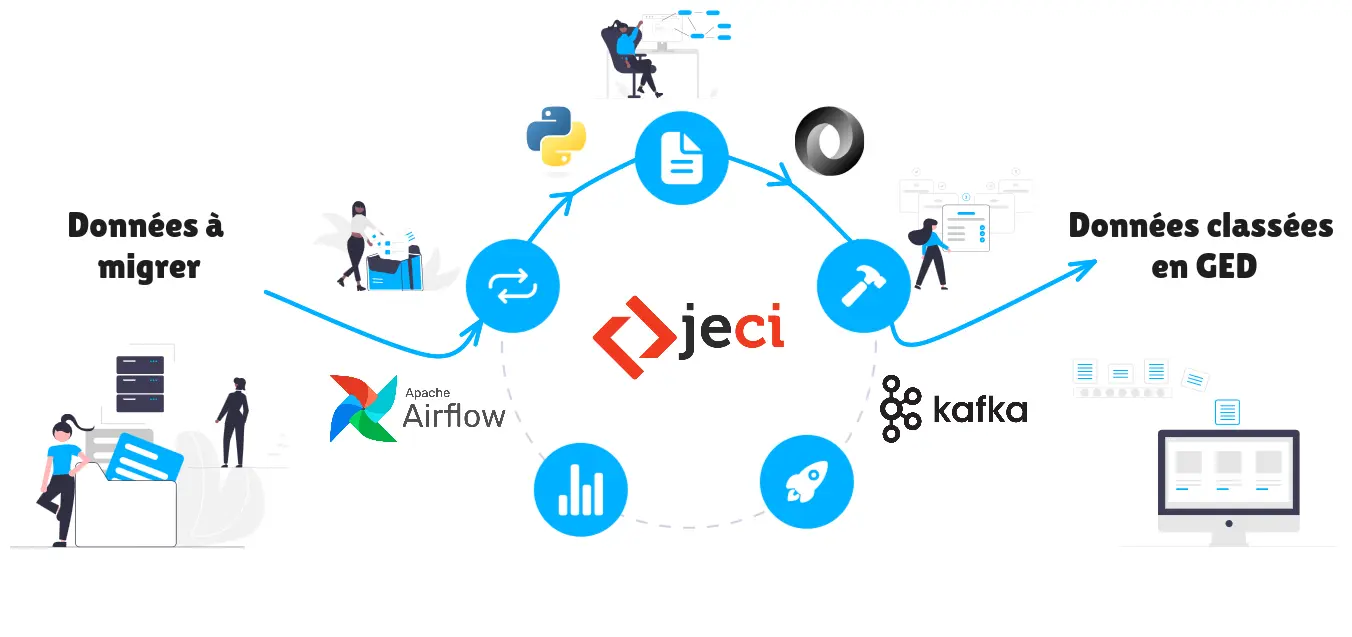
À quoi sert la reprise de donnée ?
Cela permet la reprise en masse de documents ou de contenu dans un minimum de temps.
Plus spécifiquement, ça permet de récupérer des fichiers et une arborescence de fichiers depuis des sources diverses (Alfresco, une autre GED, un système de fichiers classique) ; puis de reproduire à l’identique ou de manière transformée l’arborescence et les métadonnées sur une autre source (Alfresco ou Pristy, ou une autre GED).
Cela s’appelle un outil “ETL” pour extract-transform-load en français : extraction, transformation et chargement.
C’est autant utilisé pour de la reprise de données d’une GED à une autre que pour de la synchronisation de données ou documents provenant de progiciel vers une GED en continu.
Les avantages de notre module
Une migration sans impact sur le serveur de production
Notre système d’injection sans être forcément asynchrone se fait en deux temps. La charge sur le serveur est donc réglable et adaptable en fonction des besoins.
On peut choisir de prioriser le temps d’injection, et donc d’augmenter la charge sur le serveur ou à l’inverse de prioriser une injection sans incidence sur la prod qui peut s’avérer plus longue, mais transparent à l’exploitation.
Gestion de l’interruption
Grâce à Kafka1, nous sommes en capacité de reprendre le processus d’injection s’il a été interrompu. En cas d’interruption volontaire – ou non – la file se met en pause et reprend là où il en était lors du redémarrage du processus.
Facilement adaptable
La technologie choisie permet de rapidement et simplement adapter notre outil à un besoin spécifique.
Le choix de scripts Python2 modulaires et simples à rédiger (notamment avec l’aide de l’IA) permet au client d’adapter directement le code à son besoin.
Pas seulement pour Alfresco
Étant spécialiste Alfresco, nous avons développé cette solution pour un besoin en ce sens.
Mais cette solution n’est pas spécifique à Alfresco. On peut la brancher vers/ou depuis d’autres sources. On peut migrer de l’Alfresco vers Alfresco, mais on pourrait aussi imaginer de l’Alfresco vers Nextcloud, du Sharepoint vers Pristy (Alfresco), du serveur de fichier vers Pristy, etc.
Pré-requis
Études des données
Une étude pour connaître l’état des données, en particulier pour s’assurer que les données sont structurées, à minimum, parce qu’on ne peut pas reprendre des données en vrac, ou au moins, il faut être en capacité de les structurer, donc de les enrichir.
Adaptation de la cible
Exemple pour Alfresco :
- l’arborescence cible doit respecter les contraintes d’Alfresco, donc on est à 2 000 nœuds par répertoire, donc 2 000 fichiers ou dossiers par répertoire, et
- limiter le nombre de métadonnées, donc utiliser 20 métadonnées par fichiers plutôt que 40, 50.
Ressources à prévoir
Cela dépend de la charge, de la volumétrie et du délai d’exécution
- Il faut que les données puissent aller d’un serveur à un autre, soit par des montages réseau, soit par des flux réseau.
- Si on a une forte volumétrie à traiter sur un court délai, il faut des grosses ressources serveurs voir plusieurs serveurs ;
- à l’inverse, si on a des données en continu, mais sur du très long terme, on n’a pas besoin d’éléments spécifiques en plus.
Conformité loi interopérabilité
Pour rappel le Référentiel Général d’Interopérabilité est en vigueur depuis “La version 2.0 du RGI est officialisée par l’arrêté en date du 20 avril 2016 (JORF n°0095 du 22 avril 2016 texte n° 1).”
Définition d’interopérabilité dans le cadre de la RGI :
Nous retiendrons la définition de Wikipedia pour le RGI. La Commission Européenne définit également ce que doit être un cadre d’interopérabilité : un cadre de niveau Européen ou European Interoperability Framework (EIF), et un cadre national d’interopérabilité par États membres ou National Interoperability Framework (NIF) […]
“Un cadre d’interopérabilité est une approche concertée de l’interopérabilité pour les organisations qui souhaitent travailler ensemble à la délivrance conjointe de services publics. Au sein de son champ d’application, il spécifie un ensemble”
Grâce à ce référentiel, vous êtes assuré de pouvoir récupérer vos données. Notre solution fourni un standard qui permet de classer les données récupérées et de les injecter de façon classer dans un nouvel outil.
En savoir plus
Articles connexes
Définitions en rapport avec l'article
- ETL
- c’est le nom générique des outils pour faire de la reprise de données. Ça veut dire Extract-transform-load (extraction, transformation et chargement)
- JSON
- JSON (JavaScript Object Notation – Notation Objet issue de JavaScript) est un format léger d’échange de données.3
- Airflow4
- c’est une plate-forme de gestion de flux de travail open source 5
- Kafka1
- projet open source sous Apache License 2.0 : “logiciel de traitement de flux pour la collecte, le traitement, le stockage et l’analyse de données à grande échelle”. 6
Notes de pas de page
Apache, Apache Kafka, and the Apache Kafka logo are registered trademarks or trademarks of The Apache Software Foundation in the U.S. and/or other countries. ↩︎ ↩︎
Python and PyCon are trademarks or registered trademarks of the Python Software Foundation. ↩︎
Source : https://www.json.org/json-fr.html ↩︎
Apache, Apache Airflow, and the Apache Airflow logo are registered trademarks or trademarks of The Apache Software Foundation in the U.S. and/or other countries. ↩︎
Source traduite du site web d’Apache Kafka : https://kafka.apache.org/powered-by ↩︎